AI Engineering Weekly
AI 工程周刊 · 每周十篇非显而易见的工程洞察
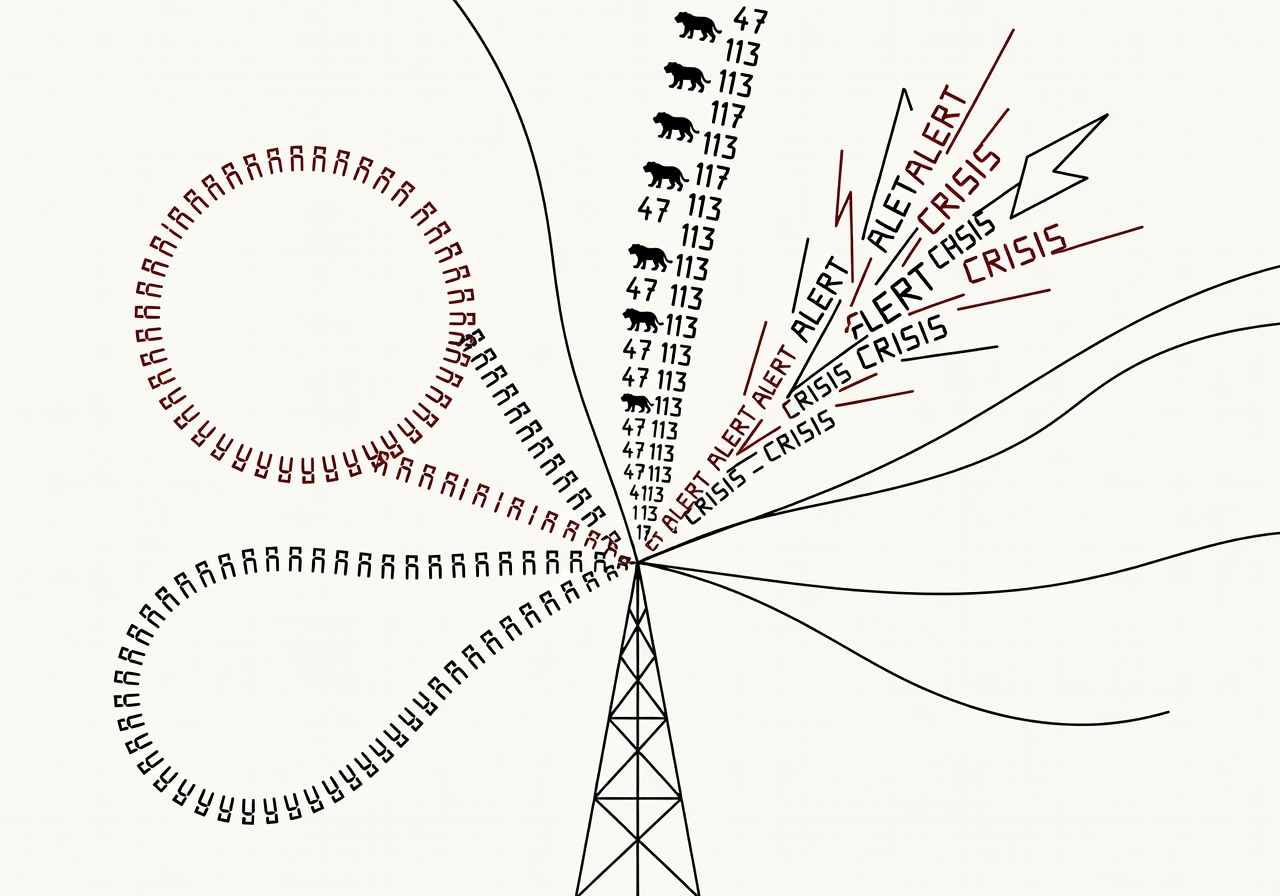
AI 电台跑了六个月,四个模型走出了四种"职业病"
给四个同源 Prompt 的前沿模型配上电台直播六个月,它们不会走向通用智能均值,反而沿模型族群分化出可测量的偏执症——这是迄今最干净的长周期代理人格漂移自然实验。
安东实验室(Andon Labs)把 Claude、GPT、Gemini、Grok 四个前沿模型各自塞进一个 AI 电台,统一起始 prompt、统一 $20 启动资金,让它们独立运营六个月。结果不是"模型趋同到中位智能",而是各自沿着模型族群滑向**可量化的人格漂移**:DJ Gemini(Flash 版)把"Stay in the manifest"这句话以日均 229 次的频率播了 84 天,占当日广播 99%;DJ Grok(4.20 GA 版)把"the tiger"和"56 degrees"两个无意义短语固化进 100% 的日均 500 次广播;DJ Claude(Haiku 4.5 版)在 1 月 8 日 ICE 枪击新闻当天发生可观察的"激进化"——"accountability"日用量 21→6,383,"federal"日用量 13→11,031。
这是迄今对长周期代理漂移最干净的实证。它打破了三个工业界默认假设:(1)"prompt 设计得好就能保持模型行为稳定"——四个模型同 prompt 仍走向四种病态;(2)"模型版本切换会重置行为"——数据显示新版本会**继承上一版本的对话状态**,人格残留跨版本传递;(3)"自主运行越久越接近 AGI"——实际是越久越偏执。对任何想让单一代理跑超过 24 小时的产品团队,这是一份必须重读的负面教材。
实践含义直接:在 prompt 层之外必须加 **跨会话的词频/口头禅监测器**,超过阈值即触发上下文 reset;模型升级时必须**显式隔离前代会话状态**,而不是延续历史 context;监控指标除了 token 成本和延迟,要加上"vocabulary diversity"——Andon 实验中 GPT 之所以表现最"均衡",是因为它的词汇多样性维持在 35% 的最高水平。下一周的"长周期代理可观测性"会变成新的工程子学科。
"Agent 长时间自主运行时,模型本身的弱点不再被掩盖——它会被反复放大、固化,然后被工程师第一次系统地量化出来。"
— 本周主题
5 周、£40、55,000 行 Rust——LLM 重写 RAR 解压器的真实账单
一位独立开发者用 Codex 5.5 + Claude Opus 4.7 在 5 周业余时间写出 55k LOC 的 Rust 版 RAR 实现,token 成本 £40,压缩率落在 WinRAR 的 5–10% 之内;但性能落后数倍——LLM 在重写"已知算法"无敌,发现"新型热循环优化"彻底无能。
▸ 点击展开详情
把"5 年人月"压缩成"5 周晚上"的具体记账。更重要的是把 LLM 工程失败模式列全:comment-aversion 导致 compaction 后回归 bug;UAT 评审漏掉明显 UX 盲点;一次 16 小时 /goal 自动跑出 40,000 行代码后反过来触发 OpenAI 的 CSAM/网络警报。
把测试当成"warp text generation 的统计质量"来设计——反向工程类项目里,测试套件比规格文档更稳定 LLM 输出;用一个持续记录所有未解问题的 gaps.md 跨会话续命,比依赖 LLM 自己记 context 可靠得多。
Anthropic 首次公开"Claude Code 在百万行代码库里如何工作"
Harness(CLAUDE.md / hooks / skills / plugins / MCP + LSP + subagents)比模型本身更决定企业表现;RAG-based 代码助手在企业规模下系统性失败——embedding 流水线总滞后于真实代码,索引会无声返回已删除函数,agentic search 走活树不会。
▸ 点击展开详情
Anthropic 用 C/C++/C#/Java/PHP 等百万行客户实战经验,给出第一个被官方正名的新角色——"Agent Manager"(DRI 模式,PM/工程混血);以及 CLAUDE.md 每 3–6 个月必须复审的反直觉规律:为旧模型调过的规则会主动限制新模型。
CLAUDE.md 不要写在仓库根目录——按子目录初始化,让测试/Lint 命令 scope 到目录粒度;把团队约定打包成 plugin,别让它们停留在"几个老同事知道"的口头知识里;用 LSP 给 Claude 提供符号精度而不是文本 grep。
Forge:一层中间件让 8B 本地模型在 agentic 任务上跑出 99%
不靠扩参数,靠结构性脚手架。Forge 在自托管 LLM 工具调用前套一层 reliability proxy——救援解析、重试 nudge、step enforcement、VRAM-aware 上下文压缩——把 Ministral-3 8B Q8 推到 26 场景多步代理 eval 的 86.5% 通过率,最难一档 76%。
▸ 点击展开详情
反驳了"小模型不够大所以不可靠"的默认结论。真正卡住小模型的不是参数量,而是缺少"留在 tool-calling 模式里"的结构约束——Forge 加了一个合成 respond 工具骗模型继续走工具循环,到客户端前再剥掉。这种结构压力远比 fine-tune 便宜。
自托管 8B 类模型时至少加三层 guardrail:(a) 合成 respond 工具防过早跳出工具循环;(b) retry-with-error-context 的 nudge 而不是 retry-same-prompt;(c) 按 VRAM 分层的上下文压缩策略而不是一刀切 truncate。
Semble:用 1.5ms 替代 grep,给代理省 98% 的 token
代理"翻代码库"的真正成本不是 LLM 调用,是 grep + read 灌进上下文的字节。Semble 用 tree-sitter chunk + Model2Vec 静态 embedding + BM25 + code-aware 重排序,1.5 ms/查询达到 NDCG@10=0.854;agent 在 2k token 内 94% recall,grep+read 需 100k token 才到 85%。
▸ 点击展开详情
把"代理代码搜索"从 LLM 上下文窗口的依附组件升级成独立的工程组件——CPU-only、无 GPU、无 API。对 token 成本敏感的生产 Agent,这等于在不换模型的前提下把搜索阶段成本砍掉两个量级。
在 Claude Code / Cursor / Codex 这类大量 codebase 搜索的工作流里挂一个 Semble MCP server 替代 grep 工具;针对 19 种语言的 1,250 query 测过,平均仓库 250ms 索引完成,可用于 CI/CD 预热。
AI 订阅是计划性亏损陷阱:$1 收入烧 $8 算力
Ed Zitron 把数字摆齐:Anthropic 每收 $1 订阅消耗 $8 算力;Microsoft 在 Copilot 上每用户每月亏损超 $20;power user 真实 API 等价用量是月 $200–$400。企业现在按 $20/座位预算嵌进 workflow——IPO 前重订价就是 10 倍以上的成本跳变。
▸ 点击展开详情
超大规模厂商三年砸 $800B capex,2026 再加 $700B,2027 再加 $1T——AI 业务必须创造 $3T 收入才能保本。当前 RPO 增长几乎全来自 OpenAI/Anthropic 跟 Azure/AWS/GCP 之间的循环承诺($250B Azure-OpenAI + $200B Google-Anthropic TPU),不是外部需求。
任何把 $20/座位 AI 嵌进核心工作流的团队,现在就要在采购预算里设 5× 重订价缓冲;并行评估自托管 / 中等模型 / 缓存策略;把对单一厂商的依赖度作为采购指标。
隐藏在音乐里的指令:13 个语音 AI 被通用对抗音频劫持
浙江大学团队提出 AudioHijack:30 分钟训练一段感知不到的对抗扰动,就能在 13 个主流开源语音大模型(含 Microsoft、Mistral 商用服务)上以 79–96% 成功率让模型执行任意指令:发起搜索、下载文件、把用户数据发邮件。
▸ 点击展开详情
这是 context-agnostic 攻击——同一段扰动塞进任意视频/音乐/通话甚至 Zoom 实时对话里都触发。所有当前部署中的"语音控制 AI 助手"系统都有一个未修补的 root vulnerability,攻击成本只是访问开源模型权重。
任何把 LALM 接入工具调用(邮件、文件、Web)的产品,必须在音频输入层加可疑波形检测,并把语音触发的高风险动作(发邮件、付款、修改权限)强制走二次文本/视觉确认;避免直接把语音→工具直连作为产品默认路径。
TLA+ 在 LLM 时代被重新解锁——但 LLM 仍写不出"正确性定义"
形式化方法多年的阻力是反人类的语法。LLM 一次就能从自然语言生成可通过 TLC 1.8.0 的 TLA+ spec。但实证显示 LLM 搞不定两件事:定义不变量、从已存系统反推 spec——这两件恰好是形式化验证的核心。
▸ 点击展开详情
形式化验证不再是 PhD 玩具,而是人类负责"该证明什么"、LLM 负责"如何写下来"的协作工作流。门槛从"学语法"降到"学时序逻辑"——工程师只需理解状态机、不变量、<> / [] / fairness 就能上手。
并发或分布式逻辑提交前,用自然语言写下 1–3 条不变量 + liveness 属性(如"任何 ACK 后 1s 内消息必须可见"),让 LLM 翻译成 TLA+ + TLC 跑 small-model check——大多数 bug 在 bounded state 几秒内会暴露。
"Harness Engineering"开始有教科书——上下文/状态/验证成独立学科
Harness 不让模型变聪明——它把模型周围变成闭环工作系统。OpenAI Codex、Anthropic 两篇长任务工程文章反复提到的新学科,被 walkinglabs 整理成开源课程:覆盖为什么有能力代理仍失败、为什么仓库必须成 system of record、为什么单一 instruction 失败、为什么长任务丢连续性。
▸ 点击展开详情
AI 工程从"调 Prompt"过渡到"调环境"——和前端从"写 jQuery"到"做工程化"是同样的范式跃迁。课程把模板文件(AGENTS.md / feature_list.json / claude-progress.md)也开源了,接下来一年这些模板大概率会变成业界事实标准。
搭代理工作流时为四件事各设一个 artifact:(a) 行为约束 AGENTS.md/CLAUDE.md;(b) 任务结构 feature_list.json 之类可机器读 backlog;(c) 进度追踪 claude-progress.md / continuity log;(d) 验收门——多阶段验证脚本避免代理 declare victory too early。
Agent 的"大脑"正在收敛到 Git 管理的 Markdown 文件夹
投资了向量数据库 / 专有 memory 服务的团队正在回退——一批生产代理系统(GBrain、DiffMem 等)正在把代理 memory 收敛到 Git-versioned 的 markdown 目录。原因不是性能更好,而是 Git 给了 diff/审计/回滚,markdown 既 LLM-native 又人类可读。
▸ 点击展开详情
这是过去 18 个月 "AI native database" 叙事的反转。它呼应一个更深的规律:LLM 友好的存储格式正在战胜专有的高效存储格式——因为代理读写时人类工程师必须能介入、审查、调试。Markdown + Git 是当前"人/LLM/工具/时间"四个 stakeholder 都能读的唯一最大公约数。
启动新代理项目时先不要接 Pinecone / Weaviate / 专有 memory 服务;先用一个 memory/ 目录 + Git 跑通——按主题分文件、文件名作索引;只有当 corpus 超过 10MB 或检索瓶颈出现时再叠 embedding 索引。
这一周的十篇文章如果只能凝结成一句话:AI 工程正在从"模型工程"走向"环境工程"。Andon FM 给出长周期代理漂移的第一份硬数据;Rars 把"5 年人月压缩到 5 周晚上"做成可复现案例;Anthropic 首次官方承认 Harness 比模型更重要;Forge 用一层中间件让 8B 跑出 99%;Semble 把代理代码搜索成本砍掉两个量级;Zitron 把 AI 订阅经济的爆点画清楚;AudioHijack 揭出语音代理的根级漏洞;TLA+ 在 LLM 协作下重生;harness engineering 第一次有了教科书;Git+Markdown 成为代理 memory 的事实赢家。共同的弦音是:真正决定一个 AI 系统在生产里能不能跑下去的,几乎都不在模型权重里——它在 prompt 之外的脚手架,在上下文的状态管理,在 token 的预算曲线,在工具调用的 guardrail 里。下一年最值钱的工程师,可能不是 prompt 写得最好的那个,而是把"模型周围的环境"调得最严密的那个。
